10 million records per second, on-premises to the cloud


By now, it is well known that Spectral Core database migration tooling is the most performant on the market, by some margin. Benchmarks would be good to back up such bold claims, but benchmarks are tricky and take time so let's use the next best thing - some screenshots.
When migrating data from on-premises servers to the cloud, we are typically talking about a lot of data. Tens of terabytes are not uncommon at all, nor are thousands of tables in a database.
Omni Loader is designed to remove as much complexity as possible from the migration process. It creates the target schema and loads all the data with no need of option tweaking - even for the largest and most complex projects.
We fight WAN latency with high parallelism. Multiple tables are loaded in parallel - even any table at a time is dynamically sliced into many parts copied in parallel. As disks are much slower than CPU and RAM, we completely avoid spilling out to disks during the data transformation. Data is processed completely in-memory.
To ingest data into warehousing solutions such as Microsoft Fabric, Google BigQuery, Snowflake, and others, one needs to prepare data for efficient ingestion. Parquet is a very good choice for intermediate data format because it is columnar and highly compressed. We choose our slice sizes heuristically in such a way that data warehouse can quickly ingest that data. As data is compressed on-premises (Omni Loader can run in a walled-garden), only the compressed data travels to the cloud. With columnar data format, compression is extremely efficient - typically you will end up with just 20% of the data size. As data upload is a bottleneck (right after CPU), moving 5x less data is a good thing.
Omni Loader automatically uses all CPU cores. It is even able to scale horizontally by forming a distributed migration cluster - in that case Omni Loader acts as an orchestrator to any number of external agent nodes. However, even in a single-node scenario, Omni Loader is extremely performant. The screenshots below are all of the Omni Loader in a single-node (standalone) mode, running on a 16-core AMD machine (32 logical cores).
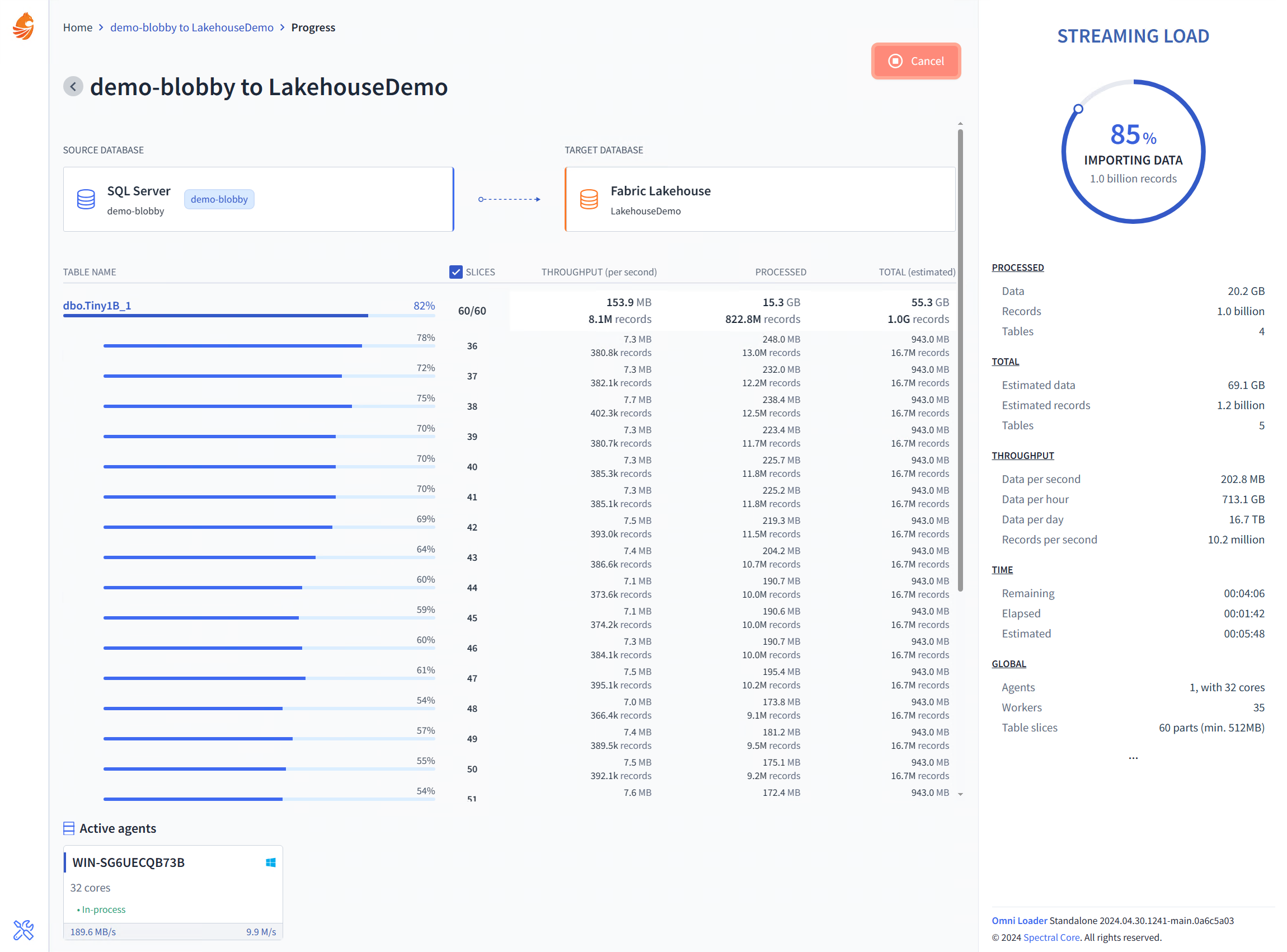
What we have above is a best-case scenario for a splashy title - a table with just five numerical columns, which means that each row contains just a bit of data. However, that table does contain a billion records so we get to show it doesn't slow us down a bit. We are able to move over 10 million records per second, going from on-prem SQL Server to the Fabric Lakehouse.
Now, what if we have a table with more data per row?

Now, "just" 2 million records per second are moved. However, take a look at the data processed per second - 307 megabytes per second! That means we are migrating over 25 terabytes of data per day.
Just to show that this performance isn't only attainable with Fabric, here is a screenshot for the BigQuery target.

Of course, should you want to migrate data exclusively in the cloud, you would get far better performance due to easy availability of high-vcpu machines and incredible network throughput.
One more thing - you may notice that throughput numbers on the right side are different than the ones listed in the active agent gadget (lower-right corner). Sidebar actually displays averages from beginning (including time to establish connections, create the tables etc.) while agent shows the current stats. We may want to unify that and display trailing 10 seconds in the future.
Omni Loader is used in production and is available today. More info is available at omniloader.com.