Migration to Fabric


Introduction
Microsoft introduced Microsoft Fabric, an all-in-one SaaS analytics solution for enterprises that offers a comprehensive suite of services, including Data Factory, Data Engineering, Data Warehousing, Data Science, Real-Time Intelligence, and Power BI.
This article focuses on our migration accelerator tools, Omni Loader and SQL Tran. These tools allow Synapse Dedicated Pool and SQL Server customers to easily migrate schema (DDL), database code (DML), and data to Fabric Data Warehouse. We will also discuss the Fabric DW First architecture as the reference architecture in this article.
Migration Challenges
An application migration project is often seen as a herculean effort. High level executives, middle management and individual contributors all agree that it can be quite complex and challenging due to several factors - data integrity, compatibility, downtime/disruption, and especially budget constraints and time/resources. Migration engagements can range from several months to several years depending on the complexity. Often the same resources must support current production environment and the migration project at the same time, spreading their resources thin. One of the biggest asks from customers is a migration tool that will provide low friction acceleration for the data migration and code migration to mitigate the challenges with migration.
The tools we provide for migration
While Spectral Core has many components in our software offering, we will only discuss the tools in scope for Fabric migration:
- Omni Loader, providing easy to use high-performance data migration
- SQL Tran, providing T-SQL code translation for DDL, tables, views, procedures, functions, with testing framework.
Fabric DW First Architecture
Fabric provides the option to choose Lakehouse or Warehouse architecture. A common customers' question is what should their Fabric target architecture be, Lakehouse or Warehouse. Microsoft Fabric decision guide: choose a data store, provides guidance on data store selection. While the articles provide all the characteristics and attributes for each data store, a simple approach is looking at “how the data is prep”? Lakehouse may be right for you if you are Spark Data Engineer, who uses Spark (Scala, PySpark, Spark SQL, R) to prep the data. Whereas Warehouse may be right for you if you are a SQL developer who uses T-SQL to prep your data. Several major benefits of the Warehouse first approach are the delta file management and maintenance that are automatically handled for you by the platform. These include optimized file writing with best practices file sizes, OPTIMIZE, Vacuum and garbage collection.
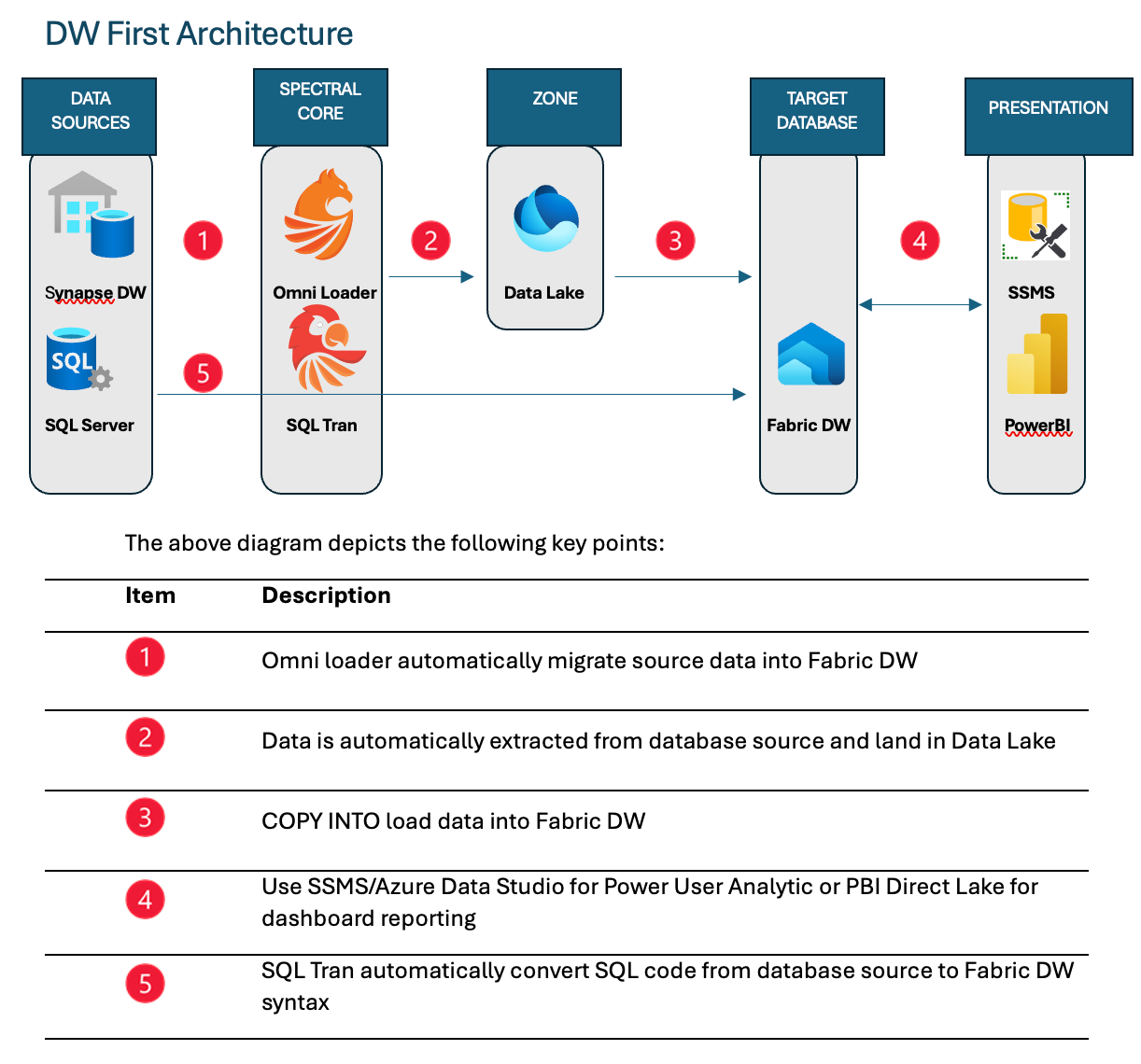
Data Migration
For Omni Loader, the current data sources supported are SQL Server on-prem, Azure SQL MI, Azure SQLDB, and Synapse Dedicated Pool. Using Omni Loader, data is automatically extracted from the source database in Parquet file format with its columnar compression to significantly reduce network traffic. Extracted Parquet files are automatically sized for performant ingestion and stored in the specified user-provided Azure storage as the Bronze layer or landing zone. For Dedicated Pool, the process uses CETAS process which provides 60 parallel data extracts from the dedicated pool compute nodes resulting in highly performant data extract. By default, the files in the Landing Zone will be removed after the data is migrated but user can change that behavior if desired.
Once all the data of any table is extracted, COPY INTO is used to ingest the data into Fabric DW. The COPY operation is automatically orchestrated and executed in parallel without blocking upload of Parquet files for other tables. Testing with the TPCH 1TB dataset, we are able to migrate 1TB in 20 minutes. That's 70 TB per day, simply by running a single executable.
Code Translation
For SQL Tran, users have the option to connect directly to the source database or use existing database file with all the objects to allow SQL Tran to read this file for the code translation. You can use the SQL script provided with SQL Tran to create a translated database SQL file. Users have the option to either export all the translated codes to flat file(s) and manually execute the code on Fabric DW or connect to Fabric DW to deploy the translated code directly to Fabric DW.
We tested a Synapse Dedicated Pool workload with 550k lines of code (SLOC) and 8772 objects (6032 tables, 1671 views, 1045 stored procedures, and 24 functions). Translation success was 99.5% and that includes all functions being marked as unsupported. When functions arrive to Fabric later this quarter and we remove that limitation detection, translation success will jump to 99.9%. Parsing was done in 3.3 seconds (169k SLOC per second), static analysis and data lineage completed in 8.8 seconds. Complete translation (which also includes assessment, static analysis, and data lineage) took 14.5 seconds, or 38.3k SLOC per second. This is with 8 vcpu deployment and we see no reason to use more vcpus at this moment but we can, if needed.
SQL Tran can create complete schema on Fabric DW so we tested that functionality. In a typical scenario where Fabric DW is empty, we measured all 8 thousand objects created in 3 minutes, which includes the time querying Fabric DW to see if any of the objects already exist. In worst-case scenario, where all the objects are present in Fabric DW so we need to drop them before recreating, total time measured was 6.5 minutes (one minute to fetch complete Fabric DW object schema information, 3 minutes to drop everything, 2.5 minutes to create all objects).
Data Consumption
Once the data and code are migrated to Fabric DW, users can take advantage of the next generation state-of-the-art analytic platform. It delivers excellent data ingestion, power run and concurrency with the flexibility to perform sub-seconds, online scale operations if your workload increases or higher concurrency requirements arise. The super users who require complex T-SQL query for detailed level analysis can use any SQL tools such as SQL Server Management Studio, Azure Data Studio). For users that use dashboards, aggregated, summarized data can use Power BI Direct Lake for the blazingly fast, highly scalable, low latency data consumption.