Introducing Hummingbird SQL parser


SQL is notoriously difficult to parse. There is a standard, ANSI SQL - you shell out over $2000 to get your hands on the specs but get little value for all that money. Each database engine rolls out own extensions to the standard, and no database implements the whole standard - so each database has its own SQL dialect. To work with a specific database, you need to know its dialect.
Parser generators are generally thought of as producing subpar code. Projects where performance matters tend to write parsers by hand. It can be done, it's a lot of work, but people still do it because they need to.
Writing a (useful) parser that covers all statements, all code constructs, keywords, types, functions etc. is incredibly time-consuming. Only a few people attempt to do it, so there are not many good SQL parsers available. Why did I do it? Let's say I was not too fond of the parser generators available at the time. I also didn't know it was so hard to write one. :) But here we are.
As we are practically done with Hummingbird parser now, I have tested its performance versus two parsers I could find that use .NET, so now we can make an apples-to-apples comparison.
First parser: ANTLR PL/SQL with C# target
ANTLR requires no introduction to anyone familiar with parser generators. Written by Terence Parr, it's a golden standard. Its grammars are robust and easy to write. It can output parsers in many languages, and ANTLR is entirely free and widely used.
Second parser: GuduSoft (sqlparser.com)
Gudu Software develops its own general SQL parser and is handling a wide variety of dialects. They are selling ready-to-use libraries in Java and .NET. Considering they offer a free trial, I was happy to use something decent besides ANTLR to test our parser against.
Third parser: Hummingbird
This one is ours and built from the ground up. Hummingbird is a parser generator. However, I will also call the parsers the generator builds Hummingbird as well, as naming is hard and life is short. I made it specifically for SQL parsing I needed for SQL Tran. It was originally built some 15 years ago and was in maintenance mode for almost all that time, with me always wishing to be able to come back to it and do it right. Luckily, I could do precisely that, and it is powering our latest software.
If you wonder, it's a recursive-descent LL(k) parser.
Comparison
I am running a quite-simple SQL SELECT script. To ensure that any parser isn't given an unfair advantage if it starts quickly (yet is slow to parse), I am also running the second and third variant with that same statement duplicated 10x and 100x, respectively. Right now, I am benchmarking the Oracle dialect.
select *
from (
select planet_name, name, radius,
row_number() over ( order by radius desc) as size_rank
from moons
where planet_name in ('Earth','Mars','Saturn')
)
where size_rank <= 3;Benchmark result

That is hard to read. I can't quickly find how to make this a nice lightbox in the Ghost blog, so you can right-click and open the image in a new tab to see it in its original size. Let's zoom into the interesting details.
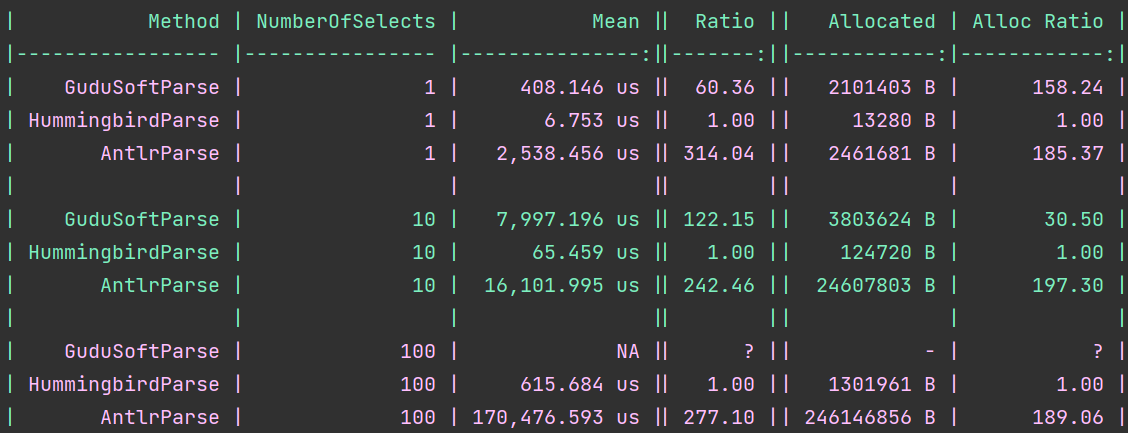
BenchmarkDotNet defines ratio as Mean of the ratio distribution ([Current]/[Baseline]), where baseline is Hummingbird parse.
We are 60x faster than Gudu for a single select and 314x faster than ANTLR. Good! For 10 selects, we are 122x faster than Gudu and 242x faster than ANTLR. In the end, for 100 selects Gudu errors out, and we are 277x faster than ANTLR.
Memory consumption is also on our side, and we allocate between 0.5% and 3% of the memory other parsers do.
For parsers, it is more important that they are correct than fast. However, if a parser is fast, there is more you can do with it.
More details in the coming posts.